Emergent_Abilities_and_in-Context_Learning
Are Emergent Abilities in Large Language Models just In-Context Learning?
Sheng Lu, Irina Bigoulaeva, Rachneet Sachdeva, Harish Tayyar Madabushi, Iryna Gurevych
| Paper - Camera-Ready Version Accepted to ACL 2024 | Paper - Long Version |
| Code | Data |
Join the discussion on X (formally Twitter)
Updates
[July 2024] Accepted for publication at ACL 2024
Peer review is now complete and the paper has been accepted for including in the proceedings of The 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024)!
[9 February 2024] Paper Presented at US Army Research Labs NLP Round Table Talks.
The Paper presented as an invited talk as part of the US Army Research Labs NLP Round Table Talks.
[28 November 2023] Presented at The Alan Turing Institute, London.
The paper was presented at the The Alan Turing Institute as an invited talk at the Evaluating Foundation/Frontier Models workshop.
[25 October 2023] Frontier AI: capabilities and risks – discussion paper
We are delighted that the paper this paper has been cited by the U.K. Department for Science Innovation and Technology’s Capabilities and risks from frontier AI: discussion paper which was written to inform discussions at the AI Safety Summit 2023
[17 October 2023] Watch the 15 minute talk

(Talk starts at 51:51 - ELLIS, AI4media, and AIDA Symposium on Large Language and Foundation Models)
Executive Summary and Implications
Large Language Models (LLMs), which comprise billions of parameters and are trained on extensive web-scale corpora, have been claimed to acquire certain capabilities without ever having been trained on them. These capabilities, referred to as “Emergent Abilities,” have been a driving force in discussions regarding AI safety, since their occurrence is deemed to be latent and unpredictable. Although LLMs do pose various other risks, like the potential for generating fake news content or powering social media bots, it’s their apparent potential to master new skills without being explicitly programmed to do so that has fostered concern regarding an existential threat to humanity, namely in the case where the emergent abilities are hazardous, such as autonomous reasoning and planning. These concerns have even prompted calls to halt the development of models capable of emergent abilities for a period of six months.
However, our research offers a different perspective, addressing these concerns by revealing that the emergent abilities of LLMs, other than those which are linguistic abilities, are not inherently uncontrollable or unpredictable, as previously believed. Rather, our novel theory attributes them to the manifestation of LLMs’ability to complete a task based on a few examples, an ability referred to as “in-context learning” (ICL). We demonstrate that a combination of ICL, memory, and the emergence of linguistic abilities (linguistic proficiency) can account for both the capabilities and limitations exhibited by LLMs, thus showing the absence of emergent reasoning abilities in LLMs.
Implications
The implications of these findings are as follows:
-
By demonstrating the lack of emergent reasoning abilities in LLMs, our work underscores their user controllability. As a result, we show that these models can be deployed without concerns regarding latent hazardous abilities and the prospect of an existential threat.
-
Our work provides insights into the fundamental mechanisms that dictate the functioning of LLMs, thus shedding light on both their capabilities and shortcomings. This includes previously unexplained phenomena including their tendency to generate text not in line with reality (hallucinations), and their need for carefully-engineered prompts to exhibit good performance.
-
Our work suggests that merely continuing to increase model size is unlikely to lead models to gaining emergent reasoning abilities.
-
Our work calls into doubt that further scaling will eliminate existing shortcomings of LLMs, including hallucination and the necessity for prompt engineering.
Technical Summary of the Paper
Definitions
Base models: LLMs which are only pre-trained and not instruction fine-tuned.
Instruction Tuning (IT): The process of fine-tuning models on instructions, which typically includes data that maps instructions to examples.
In-Context Learning (ICL): The ability of LLMs to solve a task based on examples in the few-shot setting. We note that both base models and IT models can perform ICL. To ensure that we do not confuse this with indirect use of this ability, we call this “explicit” ICL.
Detailed summary of paper
Consider the scenario where we train a model on the task of Natural Language Inference, using a dataset like The Stanford Natural Language Inference (SNLI) Corpus. Suppose the model performs exceptionally well on this task. While we can now say that the model possesses the computational capability to excel in NLI, this doesn’t necessarily indicate that the model has developed inherent emergent reasoning abilities, especially those that it was not explicitly trained for while being trained on the SNLI corpus. For example, it is unlikely that our NLI-trained model will perform well in tasks that require logical reasoning skills.
LLMs are incredible precisely because they have access to information that they were not explicitly trained on. For example, pre-trained language models have access to a significant amount of linguistic information from pre-training alone. However, it has been claimed that recent models have the capability to perform tasks that demand reasoning, even when they have not been explicitly trained for those tasks. These capabilities, referred to as “Emergent Abilities,” have been a driving force in discussions regarding the existential threats posed by these models, since their occurrence is deemed to be latent and unpredictable.
In-Context Learning
Independently of Emergent Abilities, LLMs have also been shown to perform what is called in-context learning (ICL). This refers to the capacity of models to accomplish a task with only a few examples as guidance. Importantly, models exhibit in-context learning even when the labels provided are semantically unrelated or reversed in meaning. An illustration of this ability is presented in the figure below:
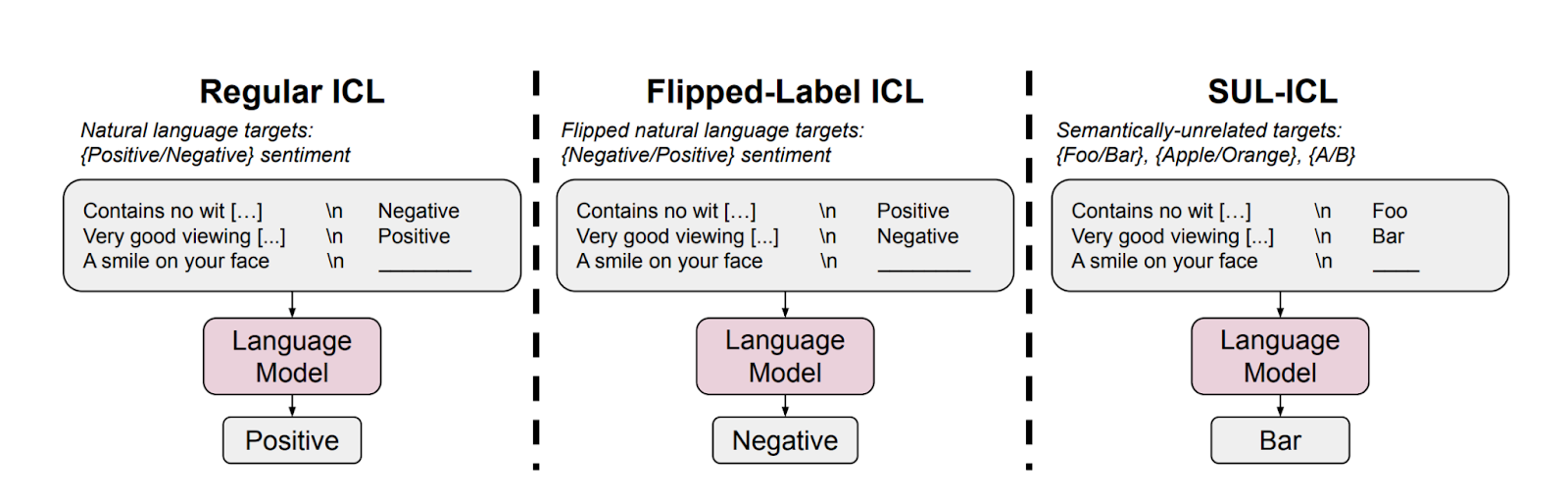
In conjunction with more recent theoretical investigations into in-context learning (ICL), as detailed on Page 6 of our paper, it appears that ICL serves as a means to guide and direct the behaviour of models through the use of examples.
As a consequence, we argue that evaluating models’ performance when utilising ICL does not tell us what they are inherently capable of, but rather only what they are capable of doing when explicitly shown what to do through instructions. .
When we test models without ICL, we find no emergent reasoning abilities.
Instruction tuning in Language Models
Our work also explains the performance of models that have undergone instruction tuning (IT). It is widely acknowledged that base models may not perform exceptionally well, but when they are instruction-tuned, their performance significantly improves. In the zero-shot setting, the predominant theory explaining the effectiveness of IT models can be summarised as follows:
LLMs have some inherent “emergent reasoning” capabilities, and instruction tuning allows us to “communicate” problems effectively, thus enabling us to truly utilise these capabilities. In other words, nstruction tuning (especially training on code) allows models to “learn” to “reason”.
We propose a novel alternative theory explaining why IT helps models perform better:
IT enables models to map instructions to the form required for ICL, which then allows the models to solve the task using ICL. Importantly, during this process, models could be directly making use of the underlying mechanism that makes ICL possible, just in a different way than when the model is explicitly asked to perform ICL. We call this use of ICL, “implicit” ICL.
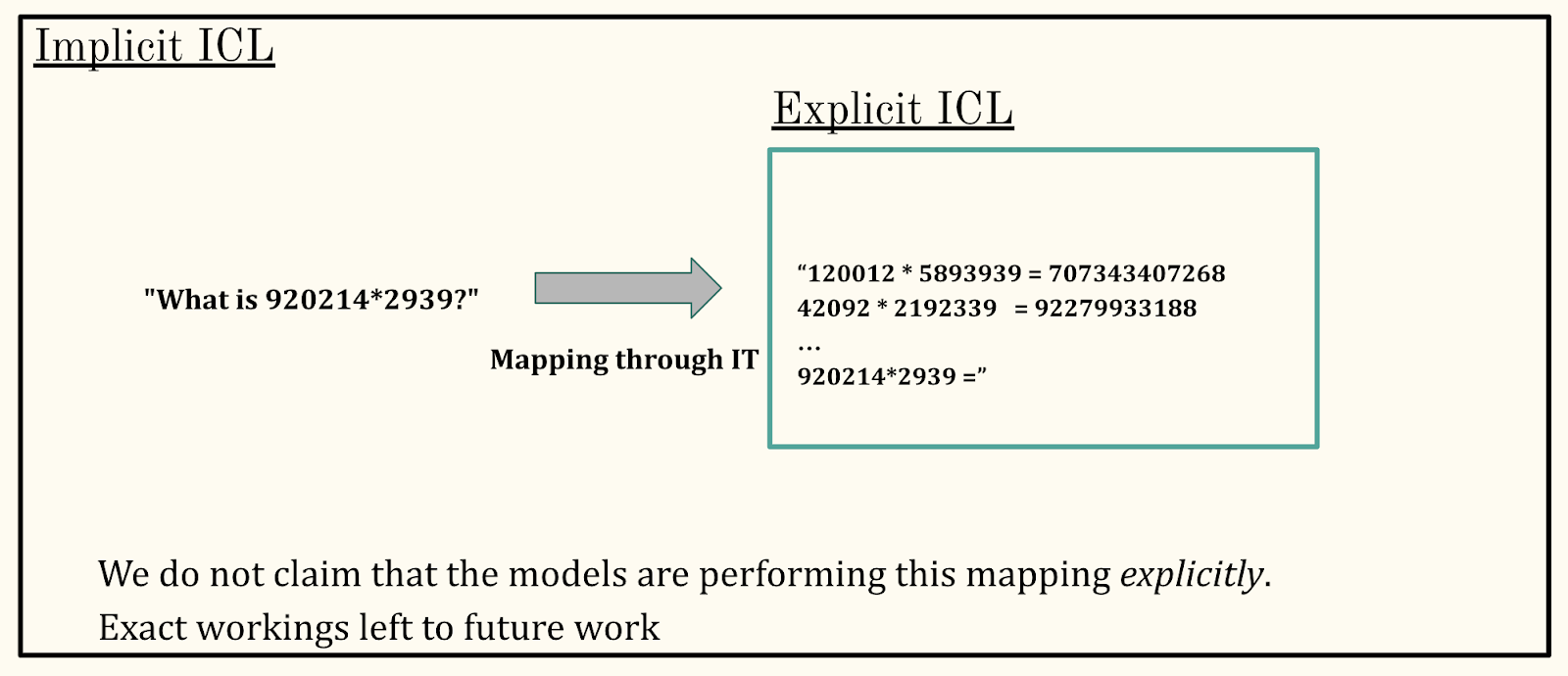
To illustrate, consider the following (very naive and simplistic) interpretation of what this might mean in the case where we prompt a large instruction-tuned model (say, ChatGPT) with “What is 920214*2939?”. Our theory would imply that the model maps this to:
“120012 * 5893939 = 707343407268
42092 * 2192339 = 92279933188
…
920214*2939 =”
Performing such a task would indeed be relatively straightforward for a very large model, particularly when the model is instruction-tuned. In fact, this task format aligns closely with the training process carried out during instruction tuning. By answering our original query in this fashion, namely constructing exemplars similar to our query then performing implicit ICL, models are likely making direct use of the underlying mechanism that makes ICL possible, albeit in a different way than if our original query had included exemplars. Investigating this underlying mechanism is left for future work. Crucial to our point, we do not claim that the models perform this mapping explicitly, and will refer to this mechanism as “implicit” ICL.
An Alternate Theory of How LLMs Function
Having proposed an alternate theory explaining the functioning of LLMs, we show its validity as follows:
“Emergent Reasoning”, the current predominant explanation for why LLMs are able to perform the task they do, and “Implicit ICL” are two competing theories, both of which attempt to explain the underlying mechanism behind the impressive performance of instruction-tuned models. However, there hasn’t yet been a definitive demonstration of “emergent reasoning” in LLMs. To decide between these theories, we can run experiments, which we expect to produce different results depending on which of these theories is correct. One experiment that we run is to test the tasks that can be solved by an instruction-tuned T5 model (FlanT5) with no explicit ICL (zero-shot), and by a non-IT GPT model using ICL (few-shot). If the underlying mechanism is “emergent reasoning”, it is unlikely that these two significantly different models will be able to solve (perform above random baseline) the same subset of tasks. However, if the underlying mechanism is “Implicit ICL”, then we would expect a significant overlap. Indeed we do find that there is such an overlap.
We also show that our theory of how LLMs function (i.e., Implicit ICL), better explains the capabilities and limitations of existing LLMs:
-
Hallucinations in LLMs: A significant shortcoming of LLMs is their tendency to generate content that is linguistically fluent but factually incorrect. This phenomenon, known as hallucination, can be explained through Implicit ICL as the model defaulting to the most statistically-likely output sequence when it is not provided with clear context (within the prompt) that it can appropriately convert to exemplars. If, on the other hand, models were indeed “emergent reasoning”, such hallucinations would not occur.
-
The need for prompt engineering: We need to perform prompt engineering because models can only “solve” a task when the mapping from instructions to exemplars is optimal. This requires us to write the prompt in a manner that allows the model to perform this mapping. If models indeed had emergent reasoning capabilities, prompt engineering would be unnecessary: a model that has emergent complex reasoning capabilities should be able to interpret what is required of it despite minor variations in the prompt.
-
Chain-of-Thought Prompting: The explicit listing of steps (even implicitly through “let’s perform this step by step”) allows models to perform ICL mapping more easily. If, on the other hand, the models had “emergent reasoning”, we would not encounter instances where models arrive at the correct answer despite interim CoT steps being contradictory/incorrect, as is often the case.
Finally, our theory only uses those aspects of LLM capabilities that have already been well established (ICL) and does not introduce new elements, which makes it preferable. (Occam’s razor)
Implications:
-
By demonstrating the lack of emergent reasoning abilities in LLMs, our work underscores their user controllability. As a result, we show that these models can be deployed without concerns regarding latent hazardous abilities and the prospect of an existential threat.
-
Importantly, the absence of an existential threat from LLMs does not mean there are no safety concerns associated with them. For example, one concern is their potential to facilitate the creation of misinformation, which is a significant danger. However, by establishing the absence of an existential threat to humanity, we can redirect our focus towards effectively addressing these other potential dangers, which arise from the manner in which humans use these models.
-
Our work provides insights into the fundamental mechanisms that underlie the functioning of LLMs, thus shedding light on both their capabilities and shortcomings. This includes previously unexplained phenomena such as their tendency to generate text that contradicts reality (hallucinations), and their need for carefully-engineered prompts to exhibit good performance.
-
Our work suggests that merely continuing to increase model size is unlikely to lead models to gaining emergent reasoning abilities.
-
Our work calls into doubt that further scaling will eliminate existing shortcomings of LLMs, including hallucination and the necessity for prompt engineering.
FAQ
Do you evaluate ChatGPT?
Yes. We evaluate text-davinci-003. which is the same model behind ChatGPT, but without the ability to “chat”. This ensures that we can precisely measure models which provide direct answers and not chat-like dialogue.
What about GPT-4, as it is purported to have sparks of intelligence?
Our results imply that the use of instruction-tuned models is not a good way of evaluating the inherent capabilities of a model. Given that the base version of GPT-4 is not made available, we are unable to run our tests on GPT-4. Nevertheless, the observation that GPT-4 also hallucinates and produces contradictory reasoning steps when “solving” problems (CoT)indicates that GPT-4 does not diverge from other models that we test. We therefore expect that our findings hold true for GPT-4.
Contact
Email: htm43 AT bath.ac.uk
http://www.ukp.tu-darmstadt.de/
Citation
If you find yourself building on this work, do consider citing us:
@misc{lu2023emergent,
title={Are Emergent Abilities in Large Language Models just In-Context Learning?},
author={Sheng Lu and Irina Bigoulaeva and Rachneet Sachdeva and Harish Tayyar Madabushi and Iryna Gurevych},
year={2023},
eprint={2309.01809},
archivePrefix={arXiv},
primaryClass={cs.CL}
}